



理学部 宇宙物理・気象学科の小林 洋祐 研究員と西道 啓博 准教授は、国際共同研究チームの一員として、宇宙論データ解析の国際チャレンジプログラムを実現するための模擬データ作成と取りまとめに大きく貢献しました。
このプログラムでは、スーパーコンピュータで生成した模擬銀河分布をもとに、宇宙の成り立ちを決める基本的な数値「宇宙論パラメータ」を推定する解析が行われました。参加チームは、模擬データに埋め込まれた「正解の宇宙」の情報を知らされないまま解析を実施し、その再現性を共通の基準のもとで検証しました。
解析の結果、多くの手法が正解値を統計的誤差の範囲内で再現することが示され、さらに手法ごとの特徴や違いについても詳しく比較・考察されました。このように、「正解を隠した共通データ」を用いて複数の手法を同時に検証する試みは世界初であり、今後の宇宙観測データ解析の標準化に大きく貢献する成果となりました。
本研究成果は、米国の天文学専門誌『The Astrophysical Journal(2025年9月1日付)』に掲載されました。

図1.コンピュータシミュレーションによって再現された宇宙の大規模構造
研究の背景
宇宙の誕生から現在までを物理法則で一貫して説明することは、現代宇宙論の究極の目標です。こうした宇宙の成り立ちを描くための理論は「宇宙論モデル」と呼ばれており、現在最も広く採用されている標準的なモデルが「ΛCDMモデル」*1)です。しかし近年、一部の観測では、このモデルでは説明できないかもしれない結果も報告されており、詳しい検証が急務となっています。
1億光年以上のスケールにまで広がる物質や銀河の分布は「宇宙の大規模構造」*2)と呼ばれ、宇宙論モデルを探る重要な手がかりとして注目されています(図1)。この大規模構造の三次元地図を得るために、数百万〜数千万個の銀河を分光観測し、その位置を記録する「銀河分光サーベイ」が世界各地で進められています。代表的な例として、米国のDESI(2021年開始)、欧州のEuclid衛星 (2023年開始)、日本のすばる望遠鏡PFS(2024年開始) が挙げられます。これらの観測から得られる高精度データは、宇宙論モデルの理解をさらに深めることが期待されています。
こうした背景のもと、大規模構造を解析するために世界中で様々な方法(解析手法)が考案されてきました。しかし、それぞれの方法の精度や信頼性を同じ基準で体系的に比較・検証する取り組みはこれまで十分に行われていませんでした。そこで今回、世界各地の研究チームが協力し、共通のデータを使って様々な手法を比べ合う国際プロジェクト(データ解析チャレンジ)が立ち上げられました。
宇宙論模擬データ解析チャレンジ
このプロジェクトは、2022年5月に米国コロラド州アスペン物理学研究所で開催された国際研究会「Large-Scale Structure Cosmology beyond 2-Point Statistics」の主要テーマとして立ち上げられました。研究会では、国際的な参加者の間で活発な議論が交わされ、研究会後もオンライン会議などを通じて議論が継続されました。その結果、本プロジェクトに最適なシミュレーションデザインや、チャレンジの開催方法について最終的な合意がされました。
模擬銀河データの作成は、研究会に参加した小林研究員(当時アリゾナ大学所属)を中心としたチームが担いました。その基盤となる高速シミュレーションプログラムGINKAKUは、西道准教授らが開発を進めていたものです。本プロジェクトにおいて西道准教授らは、信頼性の高い模擬カタログを実現するため、コードの精度検証、計算時間の最適化、実行スクリプトの整備などを担当し、その成果を小林研究員らに引き渡しました。これをもとに小林研究員らがスーパーコンピュータで大規模なN体シミュレーションを実行し、現実の銀河分光サーベイに近い模擬観測データを作成しました。
模擬データを作成する際には、コンピュータ内の宇宙が従うルール、すなわち「宇宙論モデル」をあらかじめ仮定し、その上でモデルを特徴づける「宇宙論パラメータ」の具体的な値を設定する必要があります。今回のプロジェクトでは、宇宙論モデルはすべての参加者に共有されましたが、採用した宇宙論パラメータの値は非公開とされました。
解析チャレンジに参加する各チームには、そうして作られた模擬データだけが配布され、パラメータ値を知らされないまま独自の手法で推定を行いました。データ作成チームは、得られた結果を回収し、データ作成時に実際に使用された「正解値」と照合し、統計誤差の大きさや正解値の再現性を評価した上で、結果をすべての参加者に公開しました。
研究結果
今回の研究では、世界中から参加した解析チームが、模擬データから宇宙の基本的な性質(宇宙論パラメータ)を推定しました。例えば「宇宙の全エネルギーに占める物質の割合」や「宇宙の揺らぎの大きさ」など、宇宙の成り立ちを特徴づける重要な数値です。
その結果、多くのチームの推定したパラメータの範囲が、シミュレーションで実際に仮定されたパラメータ(正解)を統計的な誤差の範囲内で再現できていることが確認されました(図2)。さらに、正解が明らかになった後のフォローアップ解析によって、手法ごとの強みや特性も詳細に比較され、今後の大規模構造データの解析に役立つ重要な知見が得られました。
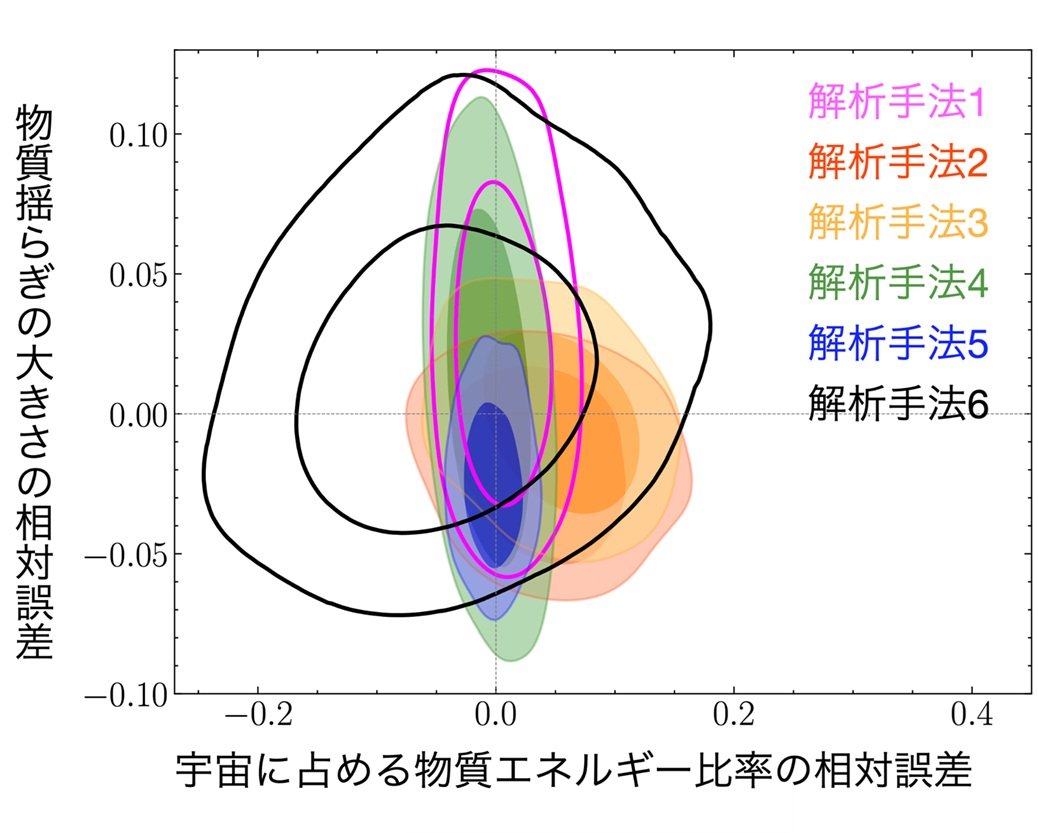
図2.解析結果の一例。横軸は「宇宙の全エネルギーのうち物質が占める割合」、縦軸は「宇宙の密度の濃淡の大きさ」を示している。いずれもシミュレーションで仮定された正解値からの差(相対誤差)として表現しているため、図の原点が正解値に対応する。色のついた領域は各解析手法による推定結果を示し、内側が68%、外側が95%の信用区間*3)にあたる。領域が小さいほど、データからより多くの情報を引き出せていることを意味する。
今後の展望
現在、日本主導で進められているすばる望遠鏡PFSの観測が本格的に進行しています。その科学的成果を確実なものとするためには、銀河の疑似データを使い、様々な解析手法が宇宙論パラメータをどれだけ正確に測定できるかを事前に検証することが不可欠です。実際に、PFSの銀河を想定した疑似データを作成し、多様な解析手法を適用して比較・評価する取り組みが行われるでしょう。その際、本研究で構築した検証プロセスは、有用な基準のひとつとして役立つと期待されます。
小林研究員のコメント
この研究では、これまで各チームがそれぞれ異なる前提や方法で整備してきた銀河分光サーベイの解析手法を、世界で初めて共通の基準のもとで検証・比較しました。このチャレンジの過程では、具体的な目標設定や疑似データの仕様などに関して非常な紆余曲折があり、そのぶん時間もかかりました。私はチャレンジの要になる疑似データの作成・配布を担当し、それだけに緊張の伴う仕事でした。しかし、銀河サーベイ解析手法の統一基準での検証が可能であることが今回示されたため、今後これを叩き台にしてさらに発展的な解析検証プロジェクトが立ち上がると期待されます。そういう意味で、今回の成果は国際的な宇宙論コミュニティにとって非常にインパクトのあるものだと思います。
掲載論文
題目:A Parameter-masked Mock Data Challenge for Beyond-two-point Galaxy Clustering Statistics
著者:The Beyond-2pt Collaboration, Elisabeth Krause, Yosuke Kobayashi, Andrés N. Salcedo, Mikhail M. Ivanov, Tom Abel, Kazuyuki Akitsu, Raul E. Angulo, Giovanni Cabass, Sofia Contarini, Carolina Cuesta-Lazaro, ChangHoon Hahn, Nico Hamaus, Donghui Jeong, Chirag Modi, Nhat-Minh Nguyen, Takahiro Nishimichi, Enrique Paillas, Marcos Pellejero Ibañez, Oliver H. E. Philcox, Alice Pisani, Fabian Schmidt, Satoshi Tanaka, Giovanni Verza, Sihan Yuan, and Matteo Zennaro
雑誌:The Astrophysical Journal
巻号:Volume 990, Number 2, Page 99
DOI:10.3847/1538-4357/ad781d
用語解説
*1) ΛCDM(ラムダ・シーディーエム)モデル:宇宙を加速膨張させるダークエネルギーとしてアインシュタインの宇宙定数(Λ)を、銀河などの天体の形成や運動を説明するために必要な未知の重力源として「冷たい(光速に比べて非常に遅い)」ダークマター(Cold Dark Matter; CDM)を採用した宇宙論モデル。重力は一般相対性理論に従うとし、初期宇宙の指数関数的膨張期インフレーションなどを前提にする。現在の観測を最小限の成分でよく説明する、最もシンプルなモデルと位置づけられている。
*2) 宇宙の大規模構造:銀河は宇宙空間にランダムに散らばっているわけではなく、集団を作りながら網の目状に広がっている。数十個規模の銀河群や、数百〜数万にも及ぶ銀河団があり、これらがさらにフィラメントと呼ばれる細い紐状の構造や、ウォールと呼ばれる壁状の構造として連なっている。一方、その間には銀河がほとんど存在しないボイドが広がる。こうした全体としての銀河の分布のことを宇宙の大規模構造と呼ぶ。その起源は、宇宙初期に存在したわずかな密度の濃淡が重力によって増幅された結果だと考えられており、宇宙の誕生や進化の歴史を読み解く手がかりとなっている。
*3) 信用区間:観測データから推定された、パラメータの真の値が含まれると期待される範囲。68%や95%といった信用度で表され、その確率で真の値が範囲内に存在することを示す。ベイズ推定という統計手法において、パラメータの不確実性を直感的に示す指標として用いられる。